Hello, World!
Hello, World! These words, which are so familiar to any programmer, will be guiding words to a new but viral branch of computer science, computational linguistics! Hello, world, for my first post, I’d like to introduce this field and how its past influences the technology of today, most notably conversational software made from artificial intelligence, like OpenAi’s popular ChatGPT.
Programs like these combine linguistics and artificial intelligence to create something that can communicate with humans with all the utilities and rules of language, making it more intuitive to talk to as if it were an all-knowing friend. However, to explore what this technology is today, it is important to look back at previous attempts to make something similar.
XiaoIce(小冰)
Released in 2014, XiaoIce is a conversational software designed by the Chinese branch of Microsoft to be a friend/companion to engage with the user, which is rather unlike ChatGPT which was designed more as a text generator than something that would try to befriend you (they are both text generators but XiaoIce wants to be your friend). XiaoIce is also quite unknown compared to OpenAi’s software, as shown in the graph from Google Trends below:
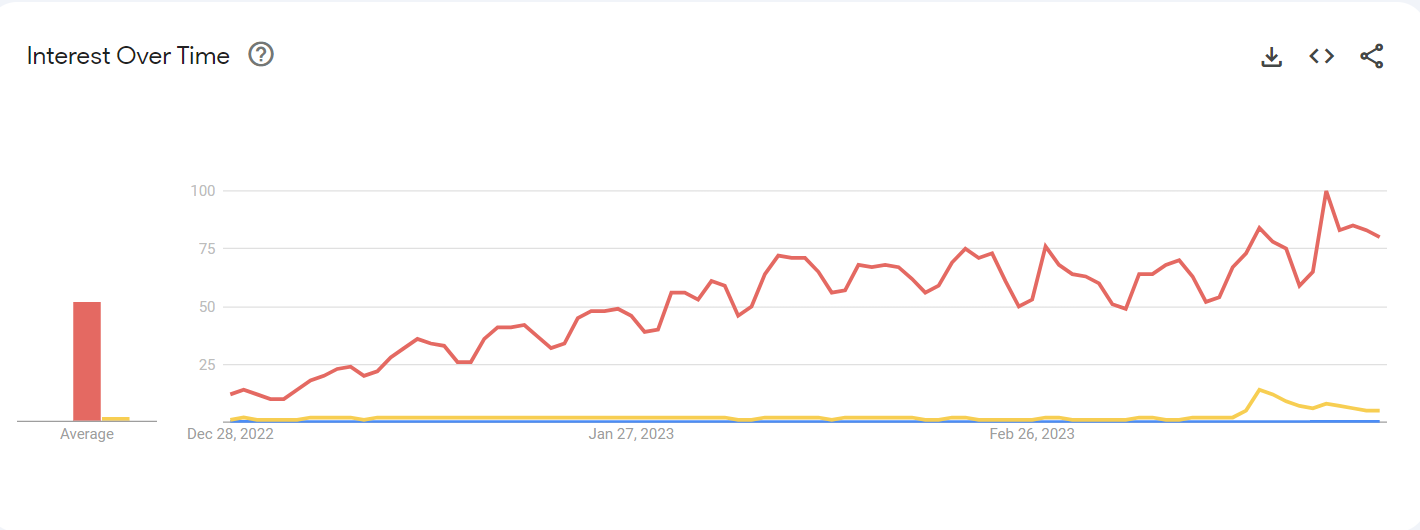
The blue line represents XiaoIce’s popularity compared to GPT-3’s yellow and ChatGPT queries in red. It is pretty clear how unknown XiaoIce is comparatively speaking, but nevertheless XiaoIce implements interesting technologies that aren’t implemented in GPT. When prompted with a statement from the user, XiaoIce will be able to label the statement as a question, statement, or “filler” (a statement that doesn’t have a purpose conversationally), and respond appropriately. This isn’t impressive by itself, but special care is taken to make these interactions as human-like as possible, which is done with two processes and two purposes. The first process is able to determine the overall purpose of the conversation, like comforting the user, helping the user look for something, joke with the user, etc. It would determine the personality of the bot in order to make it more user-friendly and helpful. The second process would decide what to reply to the user, with input from the first process to make the personality consistent.
Despite these processes, they still need to be trained to know how to do their jobs, and to train AI the system needs a way of rewarding and admonishing the program, usually based off of some statistic. In this case, the creators decided that the more engagement and messages long term, the better the program was performing. This technique eliminates problems with other possible statistics to reward the AI, since there may be cases where short term there may be certain responses to gain more engagement like arguing or giving wrong/unhelpful information, but a dissatisfied user will not come back and so the long term engagement would suffer. Therefore, the training will guide the program to be useful and friendly to retain users, instead of aiming for something unpredictable.
Why this matters
This software set a precedent for the GPTs of today, and the technology of today is only possible with the technology of the past. Think of it as playing chess, where the tactics that are hundreds of years old are still relevant and applicable today. But, not only is it still applicable, it is still being improved upon so that it can be used as a real tool in a creator’s workbench, as long as it doesn’t take over 😉.
Thanks for reading!